스터디일지
CS 면접 질문 대비 31번 ~ 40번
똥쟁이핑크
2023. 11. 17. 14:08
- 대용량 트래픽 발생 시 어떻게 대응해야 하나요?
- 나의 답변 :
1. **로드 밸런싱 (Load Balancing):**
- 트래픽을 여러 서버로 분산시켜 부하를 분산하는 로드 밸런서를 도입합니다. 이로써 각 서버에 걸리는 부하를 분산하여 전체적인 처리량을 늘릴 수 있습니다.
- 대표적으로 Nginx, HAProxy, AWS ELB(로드 밸런서) 등을 사용할 수 있습니다.
2. **캐싱 활용:**
- 정적인 콘텐츠나 반복해서 사용되는 데이터에 대한 캐싱을 적극적으로 활용합니다. 이는 웹 서버나 CDN(Content Delivery Network)를 통해 구현될 수 있습니다.
3. **분산 데이터베이스 및 샤딩 (Sharding):**
- 데이터베이스에 대한 부하를 분산시키기 위해 분산 데이터베이스를 고려하거나, 샤딩을 통해 데이터를 분할하여 처리하는 방법을 고려합니다.
4. **자동 확장 (Auto-Scaling):**
- 클라우드 환경에서는 서버 인스턴스를 동적으로 늘리거나 축소하여 트래픽에 대응할 수 있습니다. AWS의 Auto Scaling과 같은 서비스를 이용할 수 있습니다.
5. **비동기 처리 및 큐 사용:**
- 요청에 대한 응답을 동기적으로 처리하는 것이 아니라, 비동기적으로 처리하고 필요한 경우 메시지 큐를 활용하여 백그라운드에서 처리할 수 있습니다. 이를 통해 응답 속도를 향상시킬 수 있습니다.
6. **CDN 활용:**
- Content Delivery Network을 사용하여 정적 콘텐츠를 전 세계의 다양한 위치에서 더 빠르게 제공할 수 있습니다.
7. **모니터링 및 로그 분석:**
- 트래픽 패턴을 모니터링하고 로그를 분석하여 어떤 요청이 많은지, 어디서 병목이 발생하는지를 파악합니다. 이를 통해 최적화나 대응 전략을 수립할 수 있습니다.
8. **보안 강화:**
- 대용량 트래픽은 보안 위협에 노출될 수 있습니다. DDos(분산 서비스 거부) 공격 등에 대비하여 보안 강화를 고려합니다.
9. **선제적인 용량 계획:**
- 미래의 트래픽을 예측하여 용량을 선제적으로 확보하거나, 이벤트 기간과 같이 특정 기간에 트래픽이 급증할 것으로 예상되는 경우에 대비하여 대응합니다.
참고한 사이트 :
-모범 답안 :
<aside>👉 대용량 트래픽은 웹사이트, 서버 등의 시스템에 집중적으로 큰 데이터 양이나 요청이 전송되는 현상을 의미합니다. 이는 사용자 수가 급격히 증가하거나, 데이터 전송량이 폭증하는 등의 상황에서 발생합니다.
-대용량 트래픽의 개념적 정의:
- 데이터 양의 증가 : 짧은 시간 동안 많은 양의 데이터가 전송되는 상황.
ex) 동영상 스트리밍 서비스에서 대용량 동영상이 동시에 많은 사용자에게 전송되는 경우
- 요청 수의 증가 : 짧은 시간 동안 많은 수의 사용자로부터 요청이 발생하는 상황.
ex) 특정 이벤트,프로모션,티켓 구매 등으로 인해 웹 사이트에 동시에 많은 사용자가 접속하는 경우
위와 같은 상황이 발생했을 때 대응할 수 있는 방안:
1. **로드 밸런싱**: 트래픽을 여러 서버에 분산시켜 부하를 줄입니다.
2. **스케일링**: 필요에 따라 서버 자원을 확장합니다. 클라우드 환경에서는 자동 스케일링 기능을 활용할 수 있습니다.
3. **캐싱**: 자주 사용되는 데이터나 페이지를 캐시에 저장하여 빠르게 제공합니다.
4. **트래픽 제한**: 사용자나 IP 주소별로 요청 횟수를 제한하여 서버에 부담을 줄입니다.
5. **DDoS 대비**: DDoS 공격 대비 전용 솔루션을 도입하거나, 클라우드 서비스 제공자의 DDoS 보호 기능을 활용합니다.
6. **모니터링**: 시스템의 상태를 실시간으로 모니터링하여 문제가 발생하면 즉시 대응합니다.
7. **비상 계획 마련**: 트래픽 급증 시 미리 준비된 비상 계획을 실행합니다.
예를 들어, 간소화된 버전의 웹페이지를 제공하거나, 사용자에게 현재 상황을 안내하는 메시지를 표시합니다.</aside> - ORM을 사용하면서 쿼리가 복잡해지는 경우에는 어떻게 해결하는게 좋을까요?
- 나의 답변 :
ORM(Object-Relational Mapping)은 객체와 관계형 데이터베이스 간의 매핑을 담당하는 도구로, 쿼리 작성을 간소화하고 생산성을 높여줍니다. 그러나 쿼리가 복잡해지는 경우에는 ORM을 사용하면서 발생하는 성능 이슈나 유지보수 어려움 등이 발생할 수 있습니다. 이러한 상황에 대응하기 위한 몇 가지 전략은 다음과 같습니다:
1. **쿼리 최적화:**
- ORM이 생성하는 쿼리를 직접 확인하고 최적화하는 것이 중요합니다. ORM이 제공하는 기능들을 최대한 활용하면서도, 필요한 경우에는 Native Query 또는 Named Query를 사용하여 성능을 향상시킬 수 있습니다.
2. **인덱스 활용:**
- ORM이 생성한 쿼리에서 어떤 인덱스가 필요한지를 확인하고, 필요한 경우 데이터베이스에 인덱스를 추가하여 성능을 최적화합니다.
3. **Fetch 전략 조정:**
- ORM은 연관된 엔터티들을 가져오는 방식에 대한 Fetch 전략을 지원합니다. 필요한 경우 Eager Loading과 Lazy Loading을 적절히 조절하여 데이터를 효율적으로 로딩합니다.
4. **캐싱 활용:**
- ORM은 쿼리 결과를 캐싱하는 기능을 제공할 수 있습니다. 자주 사용되는 쿼리나 데이터에 대해 캐싱을 활용하여 데이터베이스 부하를 줄일 수 있습니다.
5. **DTO 사용:**
- 복잡한 쿼리 결과를 직접 엔터티로 매핑하는 대신, 필요한 필드만을 포함한 Data Transfer Object(DTO)를 사용하여 필요한 정보만을 쿼리하고 전달합니다. 이는 불필요한 데이터를 로딩하지 않고 성능을 향상시킬 수 있습니다.
6. **Batch 작업 사용:**
- 대량의 데이터를 처리해야 할 경우, ORM이 제공하는 Batch 작업을 활용하여 효율적으로 데이터를 처리합니다.
7. **Native Query 사용:**
- ORM이 복잡한 쿼리를 표현하기 어려운 경우에는 Native Query를 사용하여 직접 SQL을 작성할 수 있습니다. 이 경우에는 주의해서 사용해야 하며, SQL Injection 등의 보안 이슈를 주의해야 합니다.
8. **프로파일링 도구 활용:**
- ORM이 생성하는 쿼리를 추적하고 분석할 수 있는 프로파일링 도구를 활용하여 성능 문제를 식별하고 해결합니다.
이러한 전략들을 통해 ORM을 사용하면서도 성능 및 유지보수 측면에서 어려움을 최소화할 수 있습니다. 개발자는 ORM의 장점을 최대한 활용하면서도, 필요에 따라 네이티브 쿼리나 다른 최적화 기법들을 유연하게 적용하는 것이 중요합니다.
참고한 사이트 :
-모범 답안 :
### ORM을 사용하면서 쿼리가 복잡해지는 경우에는 어떻게 해결하는게 좋을까요?
1. **Native SQL 사용:
**ORM은 간단한 쿼리와 데이터 조작 작업에는 매우 유용하지만, 복잡한 쿼리의 경우 원시 SQL(예: PostgreSQL, MySQL, Oracle 등)을 사용하는 것이 효율적일 수 있습니다.
ORM은 매핑과 객체 지향 작업에 유용하며, 네이티브 SQL을 사용해 데이터베이스의 강력한 기능을 활용할 수 있습니다.
2. **Stored Procedure 활용:
** 복잡한 데이터베이스 로직을 저장 프로시저로 옮길 수 있습니다. 이렇게 하면 데이터베이스에서 처리되므로 네트워크 오버헤드가 감소하고 데이터베이스 성능을 최적화할 수 있습니다.
3. **ORM의 고급 기능 활용:
** 많은 ORM 프레임워크는 복잡한 쿼리를 처리하는 데 도움을 주는 고급 기능을 제공합니다. 이러한 기능을 활용하여 쿼리를 최적화하고 조인, 서브쿼리, 필터링 및 정렬과 같은 고급 데이터베이스 기능을 활용할 수 있습니다.
4. **쿼리 최적화:**
ORM을 사용할 때도 쿼리를 최적화하려는 노력을 기울이세요. 필요한 필드만 가져오고, 인덱스를 적절히 활용하며, 불필요한 조인을 피하는 등의 최적화를 수행합니다.
5. **캐싱 활용:**
복잡한 쿼리의 실행 결과를 캐시하면 빈번한 쿼리 요청에 대한 응답 시간을 줄일 수 있습니다. 이는 ORM 프레임워크 또는 캐시 라이브러리를 사용하여 구현할 수 있습니다.
6. **설계 검토:
** ORM을 사용할 때는 데이터베이스 스키마와 객체 모델 사이의 일치성을 유지하기 위한 좋은 설계 원칙을 준수하는 것이 중요합니다. 데이터베이스와 객체 사이의 매핑이 복잡해질 수 있는데, 좋은 설계는 복잡성을 최소화하고 유지보수성을 향상시킵니다.
7. **ORM 변경 고려:
** ORM 프레임워크가 프로젝트의 요구 사항을 충족하지 못하거나 복잡한 쿼리 작성이 지속적으로 어려운 경우, 다른 ORM 프레임워크나 데이터베이스 액세스 기술을 고려해 볼 수 있습니다. - GET, POST의 개념과 함께 데이터 흐름에 대해서 설명해주세요.
- 나의 답변 :
HTTP 프로토콜에서 사용되는 `GET`과 `POST`는 웹에서 데이터를 전송하는 두 가지 주요한 HTTP 메서드입니다. 각각의 메서드는 다른 목적과 특징을 가지고 있습니다.
### GET 메서드:
1. **목적:**
- 정보를 요청하기 위한 메서드로, 서버에서 어떤 데이터를 가져올 때 사용됩니다.
- 주로 데이터를 가져오는(read-only) 용도로 사용됩니다.
2. **데이터 전송:**
- URL의 쿼리 매개변수를 통해 데이터를 전송합니다.
- 예: `https://example.com/api/data?id=123`
3. **보안:**
- URL에 데이터가 노출되므로 민감한 정보를 전송하기에는 적합하지 않습니다.
- 브라우저 히스토리, 로그에 기록되므로 보안에 주의해야 합니다.
4. **캐싱:**
- 결과를 캐싱할 수 있어, 동일한 요청이 반복되면 캐시된 결과를 사용할 수 있습니다.
5. **예시:**
- 검색, 조회, 페이지 이동 등
### POST 메서드:
1. **목적:**
- 서버에 데이터를 제출하기 위한 메서드로, 데이터를 서버에 제출하여 처리하거나 업데이트할 때 사용됩니다.
- 주로 데이터를 제출하는(write) 용도로 사용됩니다.
2. **데이터 전송:**
- HTTP 요청의 본문에 데이터를 포함하여 전송합니다.
- 폼 데이터, JSON, XML 등을 전송할 수 있습니다.
3. **보안:**
- 데이터가 HTTP 본문에 포함되어 URL에 노출되지 않아 GET보다는 더 안전하게 데이터를 전송할 수 있습니다.
- HTTPS를 통해 암호화되어 전송될 경우 더욱 안전합니다.
4. **캐싱:**
- 결과를 캐싱하기 어려우며, 캐싱하더라도 안정적인 결과를 보장하기 어렵습니다.
5. **예시:**
- 회원가입, 로그인, 데이터 생성 등
### 데이터 흐름 예시:
1. **GET 요청:**
- 사용자가 웹 브라우저에서 `https://example.com/api/data?id=123`와 같은 URL로 접속하는 경우.
- 서버는 `id`가 123인 데이터를 찾아 응답합니다.
2. **POST 요청:**
- 사용자가 웹 폼을 작성하고 제출하는 경우.
- 데이터는 HTTP 본문에 포함되어 서버로 전송되며, 서버는 해당 데이터를 받아 처리합니다.
HTTP의 메서드 선택은 목적과 데이터의 특성에 따라 달라지며, GET은 주로 조회 및 검색과 같은 읽기 작업에, POST는 데이터를 제출하거나 변경하는 쓰기 작업에 주로 사용됩니다.
참고한 사이트 :
-모범 답안 :
HTTP(HyperText Transfer Protocol)는 웹에서 데이터를 전송하기 위한 기본 프로토콜입니다.
웹 브라우저와 웹 서버 간의 통신을 중개하는 주요 방법입니다.
이때 사용되는 주요 요청 메서드에는 여러 가지가 있지만, 가장 기본적이고 자주 사용되는 것은 **`GET`**과 **`POST`**입니다.
**HTTP 요청의 전반적인 흐름**:
1. **요청 시작**:
사용자가 웹 브라우저의 주소창에 URL을 입력하거나, 어떤 폼을 제출할 때 HTTP 요청이 시작됩니다.
2. **헤더 정보**:
HTTP 요청에는 다양한 헤더 정보가 포함됩니다. 이 정보에는 요청하는 리소스의 종류, 클라이언트 정보, 쿠키 등 다양한 메타데이터가 포함됩니다.
3. **서버 처리**:
웹 서버는 받은 요청을 처리합니다. 이때 필요한 데이터를 데이터베이스에서 검색하거나, 요청에 필요한 연산을 수행합니다.
4. **응답 반환**:
처리가 완료된 후, 서버는 클라이언트에게 결과를 HTTP 응답으로 전송합니다. 이 응답에는 상태 코드, 헤더 정보, 그리고 본문 데이터가 포함됩니다.**GET 요청**:- **개념**: 서버로부터 정보를 조회하기 위해 사용됩니다.
- **데이터 흐름**: 요청할 데이터는 URL의 쿼리 문자열에 포함되어 전송됩니다.
예) **`http://example.com/page?name=John&age=20`**
- **특징**: - URL에 데이터가 노출되므로 길이 제한이 있고, 민감한 정보를 전송하기에는 적합하지 않습니다.
- 웹 브라우저의 히스토리에 URL이 저장되며, 캐싱이 가능하여 동일한 요청 시 빠르게 응답을 받을 수 있습니다.
**POST 요청**
:- **개념**: 서버로 데이터를 전송하기 위해 사용됩니다. 주로 데이터 생성, 수정 등의 작업을 수행할 때 사용됩니다.- **데이터 흐름**: 전송할 데이터는 HTTP 메시지의 본문(body)에 포함되어 전송됩니다.
- **특징**: - 데이터가 URL에 포함되지 않아 GET보다는 더 많은 양의 데이터 전송이 가능하며, 민감한 정보 전송에도 적합합니다.
- 캐싱되지 않아 매번 서버가 새로운 응답을 해야 합니다.요약하면, HTTP는 웹 상에서 데이터를 전송하는 프로토콜이며, 그 내부에서 GET은 주로 정보를 조회할 때, POST는 데이터를 생성하거나 변경할 때 사용됩니다.
데이터의 이동 방식과 그 특징에 따라 적절한 요청 메서드를 선택하여 효과적인 웹 통신을 구현할 수 있습니다. - OSI 7계층에 대해 아는대로 설명해주세요.
- 나의 답변 :
OSI(Open Systems Interconnection) 모델은 네트워크 프로토콜과 통신을 계층으로 나눈 모델입니다. 이 모델은 각 계층이 명확한 역할을 수행하고 다른 계층과 독립적으로 변경될 수 있도록 설계되었습니다. OSI 모델은 총 7개의 계층으로 이루어져 있습니다.
1. **물리 계층 (Physical Layer):**
- 하드웨어와 관련된 계층으로, 전송 매체(케이블, 광섬유 등)를 통해 비트를 전송합니다.
- 전기 신호, 광 신호 등 물리적인 특성에 관련된 것들을 다룹니다.
2. **데이터 링크 계층 (Data Link Layer):**
- 물리 계층에서 전송된 비트를 그룹으로 묶어 프레임을 생성하고 에러 체크를 수행합니다.
- MAC(Media Access Control) 주소를 통해 네트워크 장치를 식별하고, 프레임의 흐름과 오류 제어를 수행합니다.
3. **네트워크 계층 (Network Layer):**
- 여러 경로 중 최적의 경로를 선택하여 패킷을 목적지까지 전달합니다.
- 라우팅, 패킷 전달, 서브넷팅 등의 기능을 수행합니다.
4. **전송 계층 (Transport Layer):**
- 데이터를 안전하게 전송하고, 흐름 제어, 오류 복구, 순서 제어 등을 수행합니다.
- 주요 프로토콜로는 TCP(Transmission Control Protocol)와 UDP(User Datagram Protocol)가 있습니다.
5. **세션 계층 (Session Layer):**
- 양 끝단 간의 세션을 관리하고, 데이터 교환을 동기화하여 통신을 유지합니다.
- 세션의 시작, 종료, 중단 등의 작업을 수행합니다.
6. **표현 계층 (Presentation Layer):**
- 데이터의 형식 변환, 암호화, 압축, 인코딩 등을 담당합니다.
- 서로 다른 데이터 형식 간의 변환을 수행하여 상위 계층이 이해할 수 있는 형태로 데이터를 제공합니다.
7. **응용 계층 (Application Layer):**
- 최종 사용자와 직접 상호작용하는 계층으로, 네트워크 서비스에 직접적인 접근을 제공합니다.
- 프로토콜에 따라 여러 응용 서비스를 지원합니다. 예: HTTP, FTP, SMTP 등.
OSI 모델은 각 계층이 서로 독립적으로 동작하기 때문에 변경이나 업그레이드가 간편하다는 장점을 가지고 있습니다. 그러나 실제로는 OSI 모델보다는 TCP/IP 모델이 더 널리 사용되고 있습니다. TCP/IP 모델은 OSI 모델을 기반으로 하며, 주로 인터넷 프로토콜 스위트에서 사용됩니다.
참고한 사이트 :
-모범 답안 :
<aside>👉 OSI(Open Systems Interconnection) 7계층은 네트워크 통신이 어떻게 이루어지는지를 계층별로 구분하여 설명하는 네트워크 표준 모델입니다.
OSI 7계층 모델은 네트워크 통신의 복잡성을 관리하기 위해 계층별로 분리된 구조를 가지며, 각 계층은 특정한 역할과 기능을 담당합니다.
이 구조를 통해 네트워크의 각 부분을 독립적으로 개발하고, 문제가 발생할 경우 해당 계층만을 집중적으로 분석하고 대응할 수 있습니다.
네트워크의 요청과 응답 :네트워크에서 요청을 할 때의 데이터는 7계층에서 1계층으로 하향식으로 요청을 보냅니다. 이 때, 최종 요청을 보내기 전 1계층에서 비트 단위의 데이터를 서버나 다른 네트워크 장비로 보낼 때, 해당 통신 매체에 맞는 신호로 데이터를 변환합니다. ( ex. 무선 통신 → 무선 신호 / 유선 케이블 → 전기적 신호 / 광섬유 케이블 → 광학적 신호)
그리고 응답을 할 때는 요청의 역순대로 상향식, 1계층에서 7계층 순으로 처리가 됩니다.(무선 신호, 전기적 신호, 광학적 신호 → 다시 비트 데이터로 변환 후 상향식 계층 통과)
다음은 OSI 7계층에 대한 설명입니다:1
. **물리 계층 (Physical Layer)**:
- **역할**: 비트 단위의 데이터를 전기적, 광학적, 무선 신호로 변환하여 전송합니다.
- **장비**: 허브, 리피터, 케이블, 통신매체 등
2. **데이터 링크 계층 (Data Link Layer)**:
- **역할**: 물리 계층을 통해 송수신되는 정보의 오류 및 흐름을 관리하며, 안전한 정보의 전달을 도와주는 역할을 합니다.
이 계층에서는 프레임이라는 데이터 단위를 사용합니다.
- **장비**: 브리지, 스위치 등
3. **네트워크 계층 (Network Layer)**:
- **역할**: 다양한 경로 중 가장 적합한 경로로 데이터를 전송하고, 경로를 변경할 필요가 있을 때 해당 경로를 결정하는 역할을 합니다.
주소 정보를 기반으로 데이터 패킷의 라우팅을 수행합니다.
- **장비**: 라우터, IP
4. **전송 계층 (Transport Layer)**:
- **역할**: 통신을 활성화하기 위한 계층으로, 데이터의 전송이 유효하고 안정적으로 이루어질 수 있도록 합니다.
신뢰성 있는 데이터 전송을 위한 오류 복구와 흐름 제어를 제공합니다.
- **주요 프로토콜**: TCP, UDP
5. **세션 계층 (Session Layer)**:
- **역할**: 송수신 기기 간의 통신 세션을 구성하고, 통신의 시작과 종료를 관리합니다.
6. **표현 계층 (Presentation Layer)**:
- **역할**: 데이터의 암호화, 복호화, 변환, 압축 등을 관리합니다.
즉, 데이터의 표현 방식을 다루며, 사용자 시스템에서 데이터의 형식을 변환합니다.
7. **응용 계층 (Application Layer)**:
- **역할**: 사용자와 가장 가까운 계층으로, 사용자 인터페이스와 애플리케이션을 제공합니다.
네트워크 서비스와 직접 관련된 모든 프로토콜을 포함합니다.
- **예시**: HTTP, FTP, SMTP, DNS 등왜 굳이 계층적인 구조를 가졌을까?
OSI 7계층 모델의 도입 이전에는 다양한 통신 기술과 프로토콜이 존재했습니다.
이런 다양성 때문에 서로 다른 시스템이나 기술 간의 상호운용성(interoperability) 문제가 발생했습니다.
각 제조사나 조직이 자체적인 방식으로 통신을 구현하였기 때문에 다른 시스템과의 통신은 복잡하고 비효율적이었습니다.
OSI 7계층 모델은 이런 문제점을 해결하기 위해 제안되었습니다.
계층별로 나누는 것의 주요 장점은 다음과 같습니다:
1. **모듈화**: 각 계층은 독립적으로 개발 및 수정이 가능하므로, 특정 계층에 문제가 발생하거나 업데이트가 필요할 경우 해당 계층만을 집중적으로 수정할 수 있습니다.
2. **상호운용성**: 표준화된 모델을 사용하므로, 다른 제조사의 장비나 시스템 간에도 통신이 가능해집니다.
3. **복잡한 네트워크 문제 해결**: 계층별로 특정 역할을 분리함으로써 복잡한 네트워크 문제를 작은 부분별로 나누어 해결할 수 있습니다.
4. **표준화**: 각 계층의 기능과 역할이 명확하게 정의되어 있으므로, 통신 기술의 표준화가 가능해집니다.
OSI 7계층 모델은 네트워크 통신의 복잡성을 관리하기 위해 계층별로 분리된 구조를 가지며, 각 계층은 특정한 역할과 기능을 담당합니다.
이 구조를 통해 네트워크의 각 부분을 독립적으로 개발하고, 문제가 발생할 경우 해당 계층만을 집중적으로 분석하고 대응할 수 있습니다.</aside> - 세션 기반 인증과 토큰 기반 인증의 차이에 대해 설명해주세요.
- 나의 답변 :
세션 기반 인증과 토큰 기반 인증은 웹 애플리케이션에서 사용자를 인증하고 권한을 부여하는 데 사용되는 두 가지 주요한 방법입니다. 각각의 방식은 동작 방식과 장단점이 다릅니다.
### 세션 기반 인증(Session-Based Authentication):
1. **동작 방식:**
- 사용자가 로그인하면 서버는 세션 ID를 생성하고 이를 쿠키 등을 통해 클라이언트에게 전송합니다.
- 클라이언트는 이 세션 ID를 저장하고, 각 요청 시에 서버에 전송하여 세션 정보를 유지합니다.
- 서버는 세션 ID를 통해 사용자를 식별하고 필요한 정보를 세션에 저장합니다.
2. **장점:**
- 간단하고 사용하기 쉽습니다.
- 서버 측에서 세션을 통해 사용자 정보를 관리하므로 클라이언트는 세션 ID만을 저장하면 됩니다.
3. **단점:**
- 서버가 세션 정보를 저장하고 관리해야 하므로 서버에 부하가 발생할 수 있습니다.
- 서버의 상태를 유지하기 위해 세션 스토리지가 필요하며, 스케일 아웃이 어려울 수 있습니다.
### 토큰 기반 인증(Token-Based Authentication):
1. **동작 방식:**
- 사용자가 로그인하면 서버는 토큰을 생성하고 이를 클라이언트에게 전송합니다.
- 클라이언트는 토큰을 저장하고 각 요청 시에 헤더나 쿼리 매개변수 등을 통해 서버에 전송하여 인증합니다.
- 서버는 토큰을 검증하고 필요한 정보를 토큰에서 추출하여 사용자를 식별합니다.
2. **장점:**
- 서버는 상태를 관리하지 않으므로 스케일 아웃이 용이합니다.
- 서버와 클라이언트 간의 독립성이 높아지고, 다양한 클라이언트에서 인증을 공유할 수 있습니다.
3. **단점:**
- 토큰은 클라이언트에 저장되어 보안에 주의해야 합니다.
- 추가적인 보안을 위해 토큰에 대한 만료 기간과 갱신 방법을 고려해야 합니다.
### 선택 기준:
- **세션 기반 인증:**
- 주로 웹 애플리케이션의 경우에 사용됩니다.
- 상대적으로 더 간단하게 구현할 수 있지만, 서버 부하와 스케일 아웃의 어려움이 있을 수 있습니다.
- **토큰 기반 인증:**
- 주로 모바일 애플리케이션, RESTful API 등에서 사용됩니다.
- 서버의 상태를 관리하지 않아 스케일 아웃이 용이하며, 다양한 클라이언트 간에도 쉽게 공유할 수 있습니다.
두 방식은 상황과 요구사항에 따라 선택되며, 보안, 확장성, 독립성 등을 고려해야 합니다.
참고한 사이트 :
-모범 답안 :
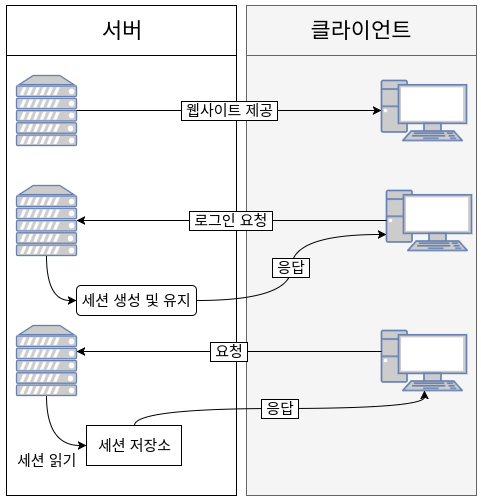
세션 기반 인증은 서버 기반의 인증 방식입니다.
사용자가 로그인하면 서버는 사용자에 대한 세션을 생성하고 세션을 식별하기 위한 세션 ID를 기준으로 정보를 저장을 합니다.
서버에서 세션 ID를 클라이언트에게 부여합니다.
클라이언트는 각 요청마다 쿠기에 세션ID를 담아서 서버로 요청을 보냅니다.
서버는 클라이언트가 보낸 세션 ID와 세션 저장소에 저장된 세션ID를 비교하여 인증을 수행합니다.
세션 기반 인증은 기본적으로 상태를 유지해야 하므로 서버 측에서 관리되어야 하며 확장성이 제한될 수 있습니다.
토큰 기반 인증과 세션 기반 인증의 큰 차이점은 유저의 정보가 서버에 저장되지 않는다는 점입니다.
토큰 기반 인증의 절차로는 사용자가 로그인하면 서버는 클라이언트에게 토큰을 부여합니다.
클라이언트는 이 토큰을 헤더에 포함시켜서 서버에 요청을 보냅니다.
서버는 각 요청마다 토큰의 유효성을 확인하여 인증을 수행합니다.
클라이언트에 저장이 되어서 서버의 부담도 덜어지고 높은 확장성을 가질 수 있습니다.
그러나 토큰이 탈취 당하면 토큰 만료시까지 계속 공격을 당할 수 있으며 토큰에 실린 payload 자체는 인코딩한 데이터로 디코딩 시 정보를 확인할 수 있어서 보안 측면에서 단점이 있습니다.
# 인증 (Authentication)> **사용자가 누구인지 확인하는 절차로, 대표적으로 회원가입, 로그인 과정이 있다.**> **일반적으로 웹 서버는 HTTP 즉, stateless 프로토콜을 사용하기 때문에 웹사이트에서 사용자가 로그인한 회원인지에 대한 인증을 관리하는 방안이 필요하다.**---
# **인가 (Authorization)**> **사용자가 요청(Request)하는 동작을 할 수 있는 권한이 있는지 확인하는 절차이다.**> **예를들어,****글을 수정하거나 삭제하는 작업은 권한이 있는 사용자만이 가능하다.****이때 권한이 있는지 여부를 확인하는 절차를 인가라고 한다.**
## 세션 기반 인증 vs 토큰 기반 인증인증 방식에는 크게 두 가지가 있다.> 두 방식의 차이는 인증 확인 증거를 어디에 저장하냐에 있다. 세션 기반 인증은 DB 서버에, 토큰 기반 인증은 클라이언트 측에 저장한다.>
### 세션 기반 인증!https://velog.velcdn.com/images%2Farthur%2Fpost%2Fff3701ad-61e8-4028-ace2-313ae9e2fa7c%2F%EC%84%B8%EC%85%98%EC%9D%B8%EC%A6%9D%EB%B0%A9%EC%8B%9D.png> 사용자의 정보를 서버측에서 기억하고 있는 인증 방식이다.> 사용자가 인증을 완료하면 서버는 인증 정보를 세션이라고 하는 별도의 공간에 저장하는데,보통 메모리 혹은 DB에 저장한다.
### 장점1. 정보가 서버에 저장되기 때문에 토큰 기반 인증에 비해 위변조 혹은 손상 우려가 없다.
### 단점
1. 서비스의 규모가 커질수록 무리를 줄 수 있다.
2. 서비스의 규모가 커커져서 사용자가 늘어나게 되면 더 많은 트래픽을 처리하기 위한 조치가 필요하다. 보통 서버를 확장하거나, 세션을 분산시키는 등의 조치가 있는데, 세션을 사용할 경우조치가 매우 복잡해진다.---
### 토큰 기반 인증!https://velog.velcdn.com/images%2Farthur%2Fpost%2Fb0248af5-1602-46e5-89c2-00a4fccf59c4%2F%ED%86%A0%ED%81%B0%EC%9D%B8%EC%A6%9D%EB%B0%A9%EC%8B%9D.png> 많은 웹 어플리케이션에서 사용하는 방식으로 JWT (JSON Web Token)을 사용한다.>
1. 서버는 아이디, 비밀번호 등으로 인증을 완료한 사용자에게 토큰을 발급한다.
2. 클라이언트는 토큰을 별도의 공간에 저장한 후, 서버에 요청(Request)할 때 헤더에 토큰을 함께 보낸다.
3. 서버는 해당 JWT의 유효성을 검사하고 인가한다.클라이언트 측에서 JWT를 저장하는 공간은 대표적으로 localStorage, Cookie 등이 있다.
### 장점
1. JWT는 클라이언트 측에서 저장하므로 서버 메모리 혹은 DB에 부담을 주지 않으며, 서버는 완전히 무상태성(Stateless)으로 남게된다.
2. 클라이언트와 서버가 독립(?, 독립이라는 단어보다는 분리되어 있다 또는 서버가 상태를 가지고 있지 않기 때문에)되어지기 때문에 확장성(Scalability)을 확보할 수 있다.
### 단점
1. JWT가 브라우저에 그대로 노출되어있으므로 위변조, 손상의 위험이 크다. (XSS 공격)
2. 한번 발급된 토큰은 임의로 만료시킬 수 없다. 따라서 토큰이 공격자(해커)에게 탈취되었다면, 공격자는 토큰이 만료될 때까지 계속 공격 할 수 있다. - JWT, Refresh, Access Token에 대해서 설명해주세요.
- 나의 답변 :
JWT(JSON Web Token), Refresh Token, Access Token은 인증 및 권한 부여를 위한 토큰 기반 인증 시스템에서 사용되는 중요한 구성 요소입니다.
### 1. JWT (JSON Web Token):
- **정의:** JWT는 JSON 포맷을 사용하여 정보를 안전하게 전송하는 토큰입니다.
- **구성:**
- Header: 토큰의 유형 및 해싱 알고리즘에 대한 정보.
- Payload: 클레임(정보)이 포함되어 있으며, 등록된(Claims), 비공개(Private), 공개(Public) 클레임으로 나뉩니다.
- Signature: 헤더와 페이로드의 내용과 비밀 키를 사용하여 생성한 서명.
### 2. Access Token:
- **역할:** 사용자의 리소스에 접근하기 위한 권한이 부여된 토큰.
- **발급:** 사용자가 로그인하면 서버에서 Access Token을 발급합니다.
- **유효 기간:** 일반적으로 짧은 기간(15분~1시간)으로 설정되며, 만료되면 Refresh Token을 사용하여 갱신 가능.
- **사용처:** API 호출 시 Authorization 헤더에 넣어 서버에 전송하여 사용자의 권한을 확인하는 데 사용.
### 3. Refresh Token:
- **역할:** Access Token이 만료된 경우 새로운 Access Token을 발급받기 위한 토큰.
- **발급:** 사용자가 로그인 시에 함께 발급되며, Access Token과는 별도로 저장되어야 합니다.
- **유효 기간:** 일반적으로 Access Token보다 긴 기간(일 수, 한 달 등)으로 설정되며, 보다 보안적으로 관리됩니다.
- **사용처:** Access Token이 만료된 경우 Refresh Token을 사용하여 새로운 Access Token을 발급받는 데 사용.
### 동작 과정:
1. 사용자 로그인 시에 서버에서 Access Token과 함께 Refresh Token을 발급합니다.
2. 클라이언트는 Access Token을 사용하여 리소스 서버에 요청합니다.
3. Access Token이 만료된 경우, 클라이언트는 Refresh Token을 사용하여 서버에 새로운 Access Token을 요청합니다.
4. 서버는 Refresh Token이 유효하면 새로운 Access Token을 발급합니다.
### 적용 예시:
- 웹 애플리케이션, 모바일 애플리케이션, API 서버 등에서 JWT, Access Token, Refresh Token을 사용하여 사용자 인증 및 권한 부여를 구현합니다.
- OAuth 2.0과 함께 많이 사용되며, 다양한 인증 및 권한 부여 플로우에서 활용됩니다.
이러한 토큰 기반의 시스템은 보안적인 측면에서 주의가 필요하며, 특히 토큰을 안전하게 저장하고 전송하는 것이 중요합니다.
참고한 사이트 :
-모범 답안 :
1. **JWT (JSON Web Token)**
- JWT는 JSON 객체를 사용하여 정보를 안전하게 전송하기 위한 컴팩트하고 URL 안전한 표현 방식입니다.
- **구조**: JWT는 세 부분으로 구성됩니다: 헤더(Header), 페이로드(Payload), 시그니처(Signature).
- **헤더**: 토큰의 타입과 사용된 알고리즘 정보를 포함합니다.
- **페이로드**: 사용자의 정보나 권한 등의 데이터를 포함합니다.
- **시그니처**: 헤더와 페이로드를 암호화한 값입니다. - 이 세 부분은 점(**`.`**)으로 구분되며, 이를 합친 문자열이 JWT 토큰이 됩니다.
- 주로 인증과 정보 교환에 사용됩니다.
2. **Access 토큰** - Access 토큰은 사용자의 세션을 대표하는 토큰입니다.
주로 API에 접근할 때 사용되며, 특정 자원에 접근할 권한을 나타냅니다.
- 일반적으로 짧은 만료 시간을 가집니다. 이는 보안 문제를 최소화하기 위함입니다. 만약 토큰이 탈취되더라도 짧은 시간 내에 만료되기 때문입니다.
- JWT 형식으로 발급될 수 있습니다.
3. **Refresh 토큰**
- Refresh 토큰은 Access 토큰이 만료되었을 때, 새로운 Access 토큰을 발급받기 위한 토큰입니다.
- 일반적으로 Access 토큰보다 긴 만료 시간을 가집니다.
- 사용자가 다시 로그인하지 않아도, Refresh 토큰을 이용해 새로운 Access 토큰을 받을 수 있습니다.
- 만약 Refresh 토큰이 탈취되면, 공격자는 새로운 Access 토큰을 계속 발급받을 수 있으므로, 저장과 관리에 주의가 필요합니다.
**요약**: JWT는 안전한 정보 전송을 위한 토큰 형식이며, Access 토큰은 사용자의 세션을 대표하고 API 접근 권한을 부여하는 짧은 수명의 토큰입니다. Refresh 토큰은 Access 토큰이 만료될 때, 새로운 Access 토큰을 받기 위한 긴 수명의 토큰입니다. - OAuth에 대해서 설명해주세요.
- 나의 답변 :
OAuth(Open Authorization)는 사용자가 자원의 소유자에게 별도의 자격 증명을 제공하지 않고도, 제3자 애플리케이션이 특정 리소스에 대한 접근 권한을 얻을 수 있게 하는 개방형 표준 프로토콜입니다. 주로 웹 및 모바일 애플리케이션에서 사용자 인증 및 권한 부여를 위해 사용됩니다.
OAuth는 다양한 버전이 존재하며, 그 중 OAuth 2.0이 현재 가장 널리 사용되고 있습니다.
### OAuth 2.0의 핵심 구성 요소:
1. **리소스 소유자 (Resource Owner):**
- 리소스(사용자 계정, 데이터 등)의 소유자로, 액세스를 제어하고자 하는 개인 또는 서비스.
2. **클라이언트 (Client):**
- 사용자의 리소스에 접근하고자 하는 애플리케이션 또는 서비스.
3. **인증 서버 (Authorization Server):**
- 리소스 소유자의 동의를 받아 클라이언트에게 액세스 토큰을 발급하는 서버.
4. **리소스 서버 (Resource Server):**
- 클라이언트가 액세스하려는 리소스가 저장된 서버.
5. **액세스 토큰 (Access Token):**
- 클라이언트가 리소스 서버에 접근할 때 사용하는 토큰. 특정 리소스에 대한 권한을 나타냄.
### OAuth 2.0 인증 흐름:
1. **Authorization Code Grant:**
- 가장 보편적으로 사용되는 인증 흐름으로, 웹 애플리케이션과 서버 간의 상호 작용에 적합합니다.
- 사용자는 인증 서버에서 리소스 소유자의 동의를 받고, 클라이언트는 액세스 토큰을 얻기 위해 인증 코드를 사용합니다.
2. **Implicit Grant:**
- 웹 프론트엔드에서 직접 액세스 토큰을 받아오는 흐름.
- 더 단순하지만, 보안상의 이슈로 권장되지 않습니다.
3. **Resource Owner Password Credentials Grant:**
- 리소스 소유자가 직접 자격 증명을 제공하여 액세스 토큰을 얻는 흐름.
- 클라이언트가 사용자의 아이디와 비밀번호를 직접 수신하므로 안전하지 않은 환경에서는 권장되지 않습니다.
4. **Client Credentials Grant:**
- 클라이언트가 자체 자격 증명을 사용하여 액세스 토큰을 얻는 흐름.
- 사용자의 정보가 필요 없는 클라이언트 간 통신에 사용됩니다.
OAuth 2.0은 다양한 환경에서 사용자 인증과 권한 부여를 효과적으로 처리할 수 있는 유연하고 안전한 프로토콜을 제공합니다.
참고한 사이트 :
-모범 답안 :
OAuth(Open Authorization)는 사용자가 웹 사이트 또는 앱을 사용할 때 다른 웹 사이트 또는 앱의 정보에 대한 접근 권한을 부여하는 오픈 스탠더드 프로토콜입니다.
OAuth를 사용하여 사용자는 자신의 데이터를 안전하게 공유하면서 다른 서비스나 애플리케이션에 대한 제어를 유지할 수 있습니다.
OAuth의 주요 구성 요소
1. 사용자 (End User): 자원 소유자이며, 자원에 대한 접근 권한을 부여하고 제어합니다.
2. 서비스 제공자 (Service Provider): 사용자의 데이터를 보유하고 있는 온라인 서비스입니다. 이 서비스는 OAuth를 사용하여 사용자가 다른 애플리케이션에서 자원에 접근할 수 있도록 허용합니다.
3. 소비자 애플리케이션 (Consumer Application): 사용자의 데이터에 접근하려는 서드파티 애플리케이션 또는 웹 사이트입니다.
4. 서버 (OAuth Server): 인증 및 권한 부여를 관리하는 서버입니다. 사용자의 인증 정보를 확인하고 액세스 토큰을 발급합니다.OAuth를 통해 사용자는 자신의 데이터를 안전하게 다른 애플리케이션과 공유할 수 있습니다.
사용자는 자신의 인증 정보를 소비자 애플리케이션에 직접 제공하지 않아도 되며, 애플리케이션은 사용자의 데이터에 접근하기 위해 OAuth를 사용하여 인증 및 권한을 얻을 수 있습니다. - HTTP 상태코드에 대해서 설명해주세요.
- 나의 답변 :
HTTP 상태 코드(HTTP Status Code)는 서버가 클라이언트에게 HTTP 요청에 대한 결과를 전달하는 데 사용되는 3자리 숫자입니다. 이 숫자는 요청이 성공적으로 처리되었는지, 혹은 어떤 문제가 발생했는지를 나타냅니다. HTTP 상태 코드는 HTTP 응답의 일부로서, 클라이언트에게 전달되어야 하는 메타 정보 중 하나입니다.
HTTP 상태 코드는 다음과 같이 5개의 범주로 나뉩니다.
1. **1xx (Informational - 정보):**
- 요청이 수신되었고, 프로세스가 계속 진행 중임을 나타냅니다.
2. **2xx (Successful - 성공):**
- 요청이 성공적으로 처리되었음을 나타냅니다.
3. **3xx (Redirection - 리다이렉션):**
- 클라이언트는 추가 동작이 필요함을 나타냅니다. 주로 리다이렉션을 통해 다른 위치로 이동하라는 것을 의미합니다.
4. **4xx (Client Error - 클라이언트 오류):**
- 클라이언트의 잘못된 요청이나 부적절한 요청으로 인한 오류를 나타냅니다.
5. **5xx (Server Error - 서버 오류):**
- 서버에서 발생한 오류로 인해 요청을 처리할 수 없음을 나타냅니다.
몇 가지 주요한 HTTP 상태 코드는 다음과 같습니다:
- **200 OK:**
- 요청이 성공적으로 처리되었습니다.
- **201 Created:**
- 요청에 의해 새로운 리소스가 생성되었습니다.
- **204 No Content:**
- 요청이 성공했지만, 응답에는 별도의 컨텐츠가 없음을 나타냅니다.
- **400 Bad Request:**
- 클라이언트의 요청이 잘못되었거나 서버가 처리할 수 없는 형식입니다.
- **401 Unauthorized:**
- 클라이언트가 인증되지 않았거나 인증이 실패했습니다.
- **403 Forbidden:**
- 클라이언트가 리소스에 접근할 권한이 없습니다.
- **404 Not Found:**
- 요청한 리소스를 서버에서 찾을 수 없습니다.
- **500 Internal Server Error:**
- 서버에서 처리 중에 오류가 발생했습니다.
- **503 Service Unavailable:**
- 서버가 일시적으로 사용 불가능 상태이거나 오버로드되었습니다.
상태 코드는 HTTP 프로토콜을 통해 효과적인 통신과 문제 해결을 가능하게 합니다. 클라이언트와 서버 간의 의사 소통에 중요한 역할을 합니다.
참고한 사이트 :
-모범 답안 :
HTTP(Hypertext Transfer Protocol)는 클라이언트와 서버 간에 웹 페이지, 파일, 이미지, 동영상 등을 전송하기 위한 통신 프로토콜입니다.
HTTP 상태 코드는 서버가 클라이언트에 반환하는 3자리 숫자로 구성된 코드입니다.
1xx (Informational): 요청을 받았고 처리 중임을 나타냅니다. 주로 프로토콜 처리를 위해 사용됩니다.
2xx (Success): 요청이 성공적으로 처리되었음을 나타냅니다. 일반적으로 200 OK가 가장 많이 사용됩니다.
3xx (Redirection): 요청을 완료하기 위해 클라이언트가 추가 작업이나 조치를 취해야 함을 나타냅니다. 예를 들어, 301 Moved Permanently나 302 Found가 있습니다.
4xx (Client Error): 클라이언트의 요청에 오류가 있음을 나타냅니다. 일반적으로 404 Not Found나 400 Bad Request가 있습니다.
5xx (Server Error): 서버가 클라이언트 요청을 처리하는 중에 오류가 발생했음을 나타냅니다. 일반적으로 500 Internal Server Error나 503 Service Unavailable이 있습니다. - CI/CD에 대해서 설명해주세요.
- 나의 답변 :
참고한 사이트 :
-모범 답안 : - TDD에 대해서 설명해주세요.
- 나의 답변 :
참고한 사이트 :
-모범 답안 : - 프로세스와 쓰레드에 대해서 설명하고 그 차이에 대해서 설명해주세요.
- 나의 답변 :
참고한 사이트 :
-모범 답안 : - 멀티프로세스와 멀티쓰레드의 특징에 대해 설명해주세요.
- 나의 답변 :
프로세스와 스레드는 컴퓨터에서 실행되는 작업을 관리하는 데 사용되는 개념입니다. 이들은 멀티태스킹 환경에서 여러 작업을 동시에 처리하기 위한 기본적인 단위들로 사용됩니다.
### 프로세스(Process):
1. **정의:**
- 프로세스는 실행 중인 프로그램으로, 운영체제에 의해 독립된 메모리 공간과 자원(파일, I/O 등)이 할당되어 실행 중인 상태입니다.
- 각 프로세스는 독립된 주소 공간을 가지며, 다른 프로세스의 자원에 직접 접근할 수 없습니다.
2. **특징:**
- 프로세스는 각각 독립적인 실행 흐름을 가지며, 서로 영향을 받지 않습니다.
- 프로세스 간 통신(IPC)을 통해 데이터를 주고받을 수 있습니다.
- 프로세스 간 전환은 쓰레드 간 전환보다 오버헤드가 큽니다.
3. **장점:**
- 안정성이 높습니다. 한 프로세스의 오류가 다른 프로세스에 영향을 미치지 않습니다.
- 병렬 처리가 가능합니다.
### 스레드(Thread):
1. **정의:**
- 스레드는 프로세스 내에서 실행되는 작업의 기본 단위로, 프로세스 내에서 공유된 자원(메모리, 파일 등)을 사용합니다.
- 스레드는 프로세스의 자원을 공유하며, 동시에 여러 작업을 수행할 수 있습니다.
2. **특징:**
- 스레드는 프로세스 내의 주소 공간을 공유하므로, 데이터를 공유하기가 쉽습니다.
- 각 스레드는 독립적인 실행 흐름을 가지지만, 메모리 공간을 공유하기 때문에 서로 영향을 받을 수 있습니다.
- 스레드 간 통신이 비교적 간단하며, 프로세스 간 통신보다 빠릅니다.
3. **장점:**
- 자원 공유로 인한 효율적인 작업 처리가 가능합니다.
- 오버헤드가 낮아 병렬성이 높습니다.
### 프로세스와 스레드의 차이:
1. **독립성:**
- 프로세스는 독립적인 주소 공간을 가지며, 서로 영향을 받지 않습니다.
- 스레드는 프로세스 내의 주소 공간을 공유하므로, 하나의 스레드에서 발생한 오류가 다른 스레드에 영향을 미칠 수 있습니다.
2. **통신:**
- 프로세스 간 통신은 IPC를 통해 이루어지며, 상대적으로 복잡합니다.
- 스레드 간 통신은 메모리 공간을 공유하므로 비교적 간단하게 이루어집니다.
3. **오버헤드:**
- 프로세스 간 전환은 오버헤드가 큽니다.
- 스레드 간 전환은 오버헤드가 작아 프로세스 간 전환보다 효율적입니다.
4. **생성 및 소멸:**
- 프로세스는 별도의 프로세스를 생성하고 종료하는데 시간이 오래 걸립니다.
- 스레드는 프로세스 내에서 스레드를 생성하고 소멸하는데 상대적으로 더 빠릅니다.
프로세스와 스레드는 각각의 특징에 따라 적절한 상황에서 선택되며, 프로그램의 목적과 효율성에 따라 다르게 활용됩니다.
참고한 사이트 :
-모범 답안 : - 쿼리 최적화에 대해 설명해주시고 방법에 대해 설명해주세요.
- 나의 답변 :
쿼리 최적화(Query Optimization)는 데이터베이스에서 쿼리의 실행 계획을 최적화하여 효율적으로 데이터를 검색하고 반환하는 프로세스입니다. 목적은 데이터베이스 성능을 향상시키고 시스템 리소스를 효율적으로 활용하는 것입니다. 쿼리 최적화는 데이터베이스 성능 향상에 중요한 역할을 합니다.
### 쿼리 최적화 방법:
1. **적절한 인덱스 사용:**
- 테이블에 인덱스를 생성하여 검색 속도를 향상시킵니다.
- WHERE 조건, JOIN 절, ORDER BY 및 GROUP BY와 같은 필드에 인덱스를 생성하는 것이 중요합니다.
2. **쿼리 작성 및 최적화:**
- 불필요한 컬럼을 선택하지 않고, 필요한 데이터만을 검색하는 쿼리를 작성합니다.
- 부적절한 JOIN 사용을 피하고, INNER JOIN, LEFT JOIN 등을 적절하게 선택하여 사용합니다.
3. **쿼리 재작성:**
- 여러 방법으로 동일한 결과를 얻을 수 있는데, 실행 계획이나 성능을 향상시킬 수 있는 쿼리로 변경하는 것이 가능합니다.
4. **통계 활용:**
- 데이터베이스에서는 통계 정보를 수집하여 최적의 실행 계획을 수립합니다.
- 통계를 기반으로 최적의 인덱스나 조인 방법을 선택하여 성능을 개선할 수 있습니다.
5. **인덱스 힌트 사용:**
- 데이터베이스 시스템에 따라 인덱스 힌트를 사용하여 특정 인덱스를 강제로 사용하도록 할 수 있습니다.
- 주의가 필요하며, 특별한 상황에서만 사용하는 것이 좋습니다.
6. **쿼리 캐싱 활용:**
- 쿼리 결과를 캐싱하여 이전에 실행한 쿼리와 동일한 결과를 빠르게 반환할 수 있도록 합니다.
- 캐싱 전략을 결정할 때 데이터의 갱신 빈도와 쿼리의 복잡성을 고려해야 합니다.
7. **분할 테이블 사용:**
- 큰 테이블을 작은 테이블로 나누어 성능을 향상시킬 수 있습니다.
- 파티셔닝이나 샤딩과 같은 기술을 활용하여 데이터를 분할하여 처리하는 방법도 있습니다.
8. **실행 계획 분석:**
- 데이터베이스 엔진이 생성한 실행 계획을 분석하여 어떻게 쿼리가 처리되는지 이해하고 최적화할 수 있습니다.
- 데이터베이스 시스템의 모니터링 및 성능 분석 도구를 활용하여 실행 계획을 확인하는 것이 도움이 됩니다.
쿼리 최적화는 데이터베이스 시스템에 따라 다르며, 데이터의 양, 구조, 사용 패턴 등을 고려하여 적절한 최적화 전략을 선택하는 것이 중요합니다.
참고한 사이트 :
-모범 답안 : - DB 로직 최소화를 하려면 어떻게 해야 할까요?
- 나의 답변 :
DB 로직 최소화는 데이터베이스 액세스 및 처리를 효율적으로 관리하여 성능을 향상시키고, 더 나은 유지보수성을 제공하는데 중요합니다. 아래는 DB 로직 최소화를 위한 몇 가지 방법입니다:
1. **인덱싱 최적화:**
- 적절한 인덱스를 사용하여 데이터 검색 속도를 향상시킵니다.
- WHERE 절에서 자주 사용되는 컬럼에 인덱스를 생성하는 것이 중요합니다.
2. **적절한 쿼리 사용:**
- 데이터베이스 쿼리를 최소화하고 효율적으로 작성합니다.
- 필요한 데이터만을 선택하고, 불필요한 JOIN이나 서브쿼리를 피합니다.
- GROUP BY, ORDER BY, DISTINCT 등이 필요한 경우에만 사용합니다.
3. **캐싱 활용:**
- 쿼리 결과를 캐싱하여 동일한 쿼리의 반복적인 실행을 방지합니다.
- 메모리나 분산 캐시 시스템을 활용하여 빠르게 결과를 반환합니다.
4. **데이터베이스 커넥션 최적화:**
- Connection Pool을 활용하여 데이터베이스 연결을 재사용하고, 연결 생성 및 소멸 오버헤드를 최소화합니다.
5. **프로시저 및 트리거 활용:**
- 복잡한 로직이나 자주 사용되는 쿼리는 데이터베이스 내에 프로시저나 트리거로 작성하여 로직을 최적화합니다.
6. **최적화된 데이터 타입 사용:**
- 데이터 타입을 최적화하여 저장 공간을 절약하고, 쿼리 성능을 향상시킵니다.
- 필요 이상으로 큰 데이터 타입을 사용하지 않도록 주의합니다.
7. **대량 데이터 작업 최적화:**
- 대량 데이터 작업은 오프라인으로 수행하거나, 효율적인 방법으로 처리할 수 있는 방법을 찾습니다.
- 배치 처리를 통해 데이터베이스에 부하를 최소화합니다.
8. **레플리케이션과 샤딩 활용:**
- 레플리케이션을 통해 읽기 작업을 여러 서버에 분산시켜 성능을 향상시킵니다.
- 샤딩을 활용하여 데이터베이스를 분할하여 처리 성능을 최적화합니다.
9. **정규화와 역정규화 조절:**
- 정규화를 통해 데이터 중복을 최소화하고, 역정규화를 통해 읽기 성능을 향상시킵니다.
- 데이터의 특성과 사용 패턴에 따라 적절한 정규화 수준을 결정합니다.
10. **인덱스, 테이블 통계 수집:**
- 데이터베이스 통계를 정기적으로 수집하여 옵티마이저가 최적의 실행 계획을 수립하도록 합니다.
- 인덱스 통계를 확인하고 필요할 경우 인덱스를 재조정합니다.
이러한 최적화는 데이터베이스 성능에 직접적인 영향을 미치며, 적절한 디자인과 관리를 통해 유지보수성도 향상시킬 수 있습니다.
참고한 사이트 :
-모범 답안 : - 테스트코드에 대해서 아는대로 설명해주시고 활용 경험에 대해서 답변해주세요.
- 나의 답변 :
테스트 코드(Test Code)는 소프트웨어의 기능이나 모듈이 의도한 대로 동작하는지를 검증하기 위해 작성된 코드입니다. 테스트 코드는 소프트웨어의 안정성을 유지하고 변경 사항이나 기능 추가에 대한 영향을 최소화하는 데 도움을 줍니다.
### 테스트 코드의 특징:
1. **자동화(Automation):**
- 테스트 코드는 자동으로 실행되어야 하며, 반복 가능하게 테스트를 수행할 수 있어야 합니다.
- 자동화된 테스트는 빠르게 실행되고 일관된 결과를 제공합니다.
2. **독립성(Independence):**
- 각 테스트 케이스는 독립적이어야 합니다. 한 테스트의 실패가 다른 테스트에 영향을 미치면 안됩니다.
3. **반복 가능성(Repeatable):**
- 언제든지 반복 가능한 결과를 제공해야 합니다. 동일한 입력에 대해 항상 동일한 출력을 생성해야 합니다.
4. **가독성(Readability):**
- 테스트 코드는 이해하기 쉬워야 하며, 코드의 의도가 명확히 드러나야 합니다.
5. **빠른 실행 속도(Fast Execution):**
- 빠르게 실행되어야 하며, 빠른 피드백을 제공하여 개발자가 빠르게 수정할 수 있도록 합니다.
### 테스트 코드의 종류:
1. **단위 테스트(Unit Test):**
- 코드의 개별 단위(함수, 메서드)가 의도한 대로 작동하는지를 테스트합니다.
- 주로 특정 함수 또는 메서드에 초점을 맞춰 작성됩니다.
2. **통합 테스트(Integration Test):**
- 여러 개의 단위를 통합하여 전체 시스템이 예상대로 작동하는지를 테스트합니다.
- 서로 다른 모듈 간의 상호 작용을 테스트하는 데 중점을 둡니다.
3. **인수 테스트(Acceptance Test):**
- 전체 시스템이 사용자의 요구사항을 충족하는지를 확인하는 테스트입니다.
- 사용자 시나리오에 기반하여 시스템의 기능을 검증합니다.
### 테스트 주도 개발(TDD: Test-Driven Development):
TDD는 테스트 코드를 먼저 작성하고, 그 후에 실제 코드를 작성하는 방식으로 개발하는 접근법입니다. TDD의 주요 단계는 다음과 같습니다:
1. **테스트 작성 단계:**
- 새로운 기능 또는 변경된 기능에 대한 테스트 코드를 먼저 작성합니다. 이 단계에서는 테스트가 실패합니다.
2. **코드 작성 단계:**
- 테스트를 통과시키기 위해 실제 코드를 작성합니다. 목표는 최소한의 코드로 테스트를 통과하는 것입니다.
3. **리팩터링 단계:**
- 테스트가 통과하면 코드를 리팩터링하여 코드의 가독성과 유지보수성을 높입니다.
TDD를 통해 코드 품질을 높이고 버그를 사전에 발견하여 개발 생산성을 향상시킬 수 있습니다. 테스트 코드는 소프트웨어 개발의 핵심 요소 중 하나로 여겨지며, 신뢰성 높은 소프트웨어를 구축하는 데 기여합니다.
트렐로 프로젝트에서 테스트 코드를 활용해 봤는데 메서드 하나하나를 단위 테스트로 코드를 짜 보았고
참고한 사이트 :
-모범 답안 : - Array, LinkedList에 대해 설명해주시고 각각 어떻게 사용하는지 말씀해주세요.
- 나의 답변 :
참고한 사이트 :
-모범 답안 : - AWS S3, EC2를 사용하는 이유와 사용 경험에 대해서 답변해주세요.
- 나의 답변 :
참고한 사이트 :
-모범 답안 : - 정렬 알고리즘에 대해서 아는대로 설명해주세요.
- 나의 답변 :
참고한 사이트 :
-모범 답안 :
{kind=link}
{kind=link}